记一次线上CPU100%的问题排查记录
某一天中午,线上突然收到告警,提示某一个服务的部分集群 CPU 使用率长时间超出100%,
由于我们是三集群部署,假设三个集群分别是A、B、C,其中 ABC 都可以被下游服务 S1 调用,而 B 集群是由于是就近访问,只能被 S2 服务调用,问题恰好出现在 B 集群。
该服务是一个典型的IO密集型应用,平时的CPU基本处于10%以下
查看服务的发版记录,发现最近一次发版记录是一天前,所以初步排除是最近的需求导致的。
某一天中午,线上突然收到告警,提示某一个服务的部分集群 CPU 使用率长时间超出100%,
由于我们是三集群部署,假设三个集群分别是A、B、C,其中 ABC 都可以被下游服务 S1 调用,而 B 集群是由于是就近访问,只能被 S2 服务调用,问题恰好出现在 B 集群。
该服务是一个典型的IO密集型应用,平时的CPU基本处于10%以下
查看服务的发版记录,发现最近一次发版记录是一天前,所以初步排除是最近的需求导致的。
今年国庆的放假日期是9月29号,因此 15 号就是抢票的高峰期,而且今年是自20年以后,出行人数最多的一个节假日,12306直接瘫痪了十几分钟,导致系统的一些问题被暴露出来。
在高峰期间,我们的单独的 Redis 集群QPS是 16W/s,期间依靠不断的扩容读节点才勉强扛住了这一波流量,Redis 读服务器的 CPU 一段时间几乎全部被打满。
在代码中看到很多逻辑都是将一些无用的字段也放在了 Redis 中,这样不仅会增加 Redis 的内存,而且在高峰期,极有可能由于一些大 key 导致 Redis 读写变慢,从而拖垮整个服务。
如果对于一些变动不是很频繁的 Key,尝试做本地缓存是一个不错的选择。一些大 Key 做好拆分,实在无法避免的,最好是进行压缩存入 Redis。
在开发的过程中,正常的业务需求通常来说都是不太复杂,主要的时间大多数都是花费在如何正确的处理异常逻辑。
下面列举几个常见的:
Jackson 的序列化
在目前 JDK8 的大量普及下,很多新的项目重构都会优先选择 LocalTime 或者 LocalDateTime 作为入参的类型,好处就是调用方不用关心时间格式问题。
在之前项目中,很多时间都是定义为 String,
例如:Jackson默认的LcoalTime 格式是 HH:mm,而如果你提供的是 HH:mm:ss,那么就会直接反序列化失败,所以在一些项目的开发过程中,需要注意的一点就是尽量对日期或者时间的字符串做一个标准化的检查,从而避免导致业务的一场。
对DB的操作一定要慎重
在代码中经常可以看到一些查询的语句会有各种条件组合,所以这一部分也是最容易遗漏的地方。要尽可能的避免在某些条件组合下导致的全表查询,以及查询的数据量过大的情况。
如果可以在业务上就预估出最大的查询量,适当的加上 limit 可以有效避免 拖垮DB 或者 OOM 的情况发生。
避免返回null
对于一些集合类型的返回值,尽量返回一个空集合来代替null,java.util.Collections#emptyList()
我们有一个服务,主要是给一些商家或者供应商查看售卖的票信息,例如报表下载和一些售票的查询等等。
因为平时用的人比较少,而且我们这边可以配置自动扩容的阈值,所以机器配置是 2C8G,两个机房分别 3 台。
项目很少发版本,最近一次的发版本还是前一个月。
在我们的日常开发中,会发现一些代码中充斥着 @Autowired,这种做法在我们的业务代码中非常的常见,但是如果仔细观察,你就会发现 IntelliJ 会出现一个 warning

不推荐使用字段进行注入???我用了这么长时间的注入方式,竟然被 Spring 不推荐了?
然后我们的其他同学就放弃了 @Autowired 注解,转而使用 @Resource 注解,虽然说 IDEA 不再告警,但是从业务的角度上来说,还是不推荐这样处理。
看到这里,顺带提一句,Spring 有哪几种构造方式?这个是经典八股了,如果没有背熟的,各打一个大板,答案是:
在多线程编程的环境中,一个变量是可以被多个线程访问并修改的,如果想让一个线程,在不影响到其他线程的情况下,修改此变量,那么就需要将该变量改成自己私有的,这就是 ThreadLocal 的作用了。
Threadlocal 可以将一个变量作为自己的私有变量,可以在本线程内随意修改并且不影响到其他线程,如下 Demo:
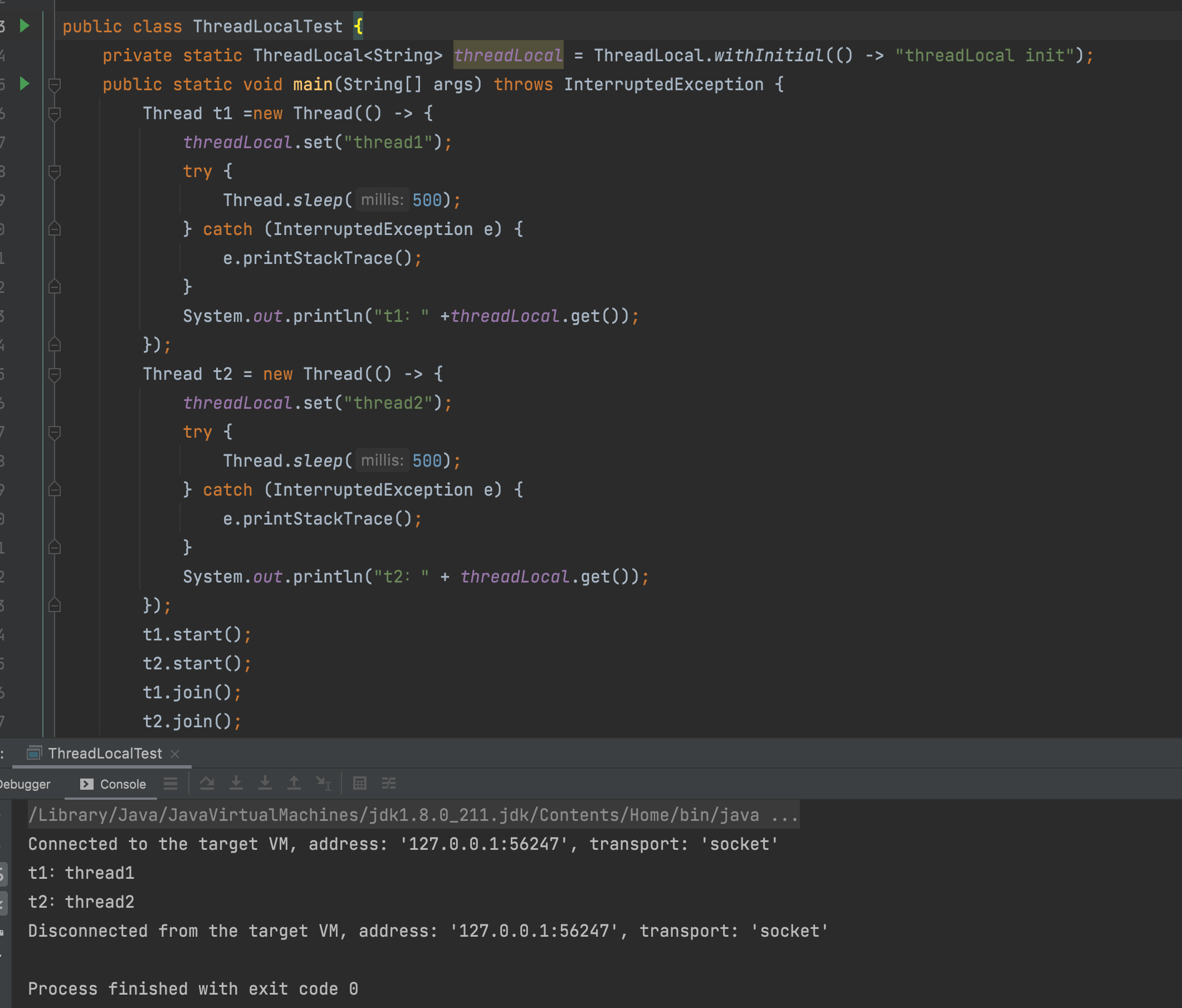
可以看到 t1 打印出 Thread1,t2 打印出 Thread2,两个线程的 ThreadLocal 都不受影响。
虽然有那么点标题党,但是确实让我损失了一杯星巴克,耽误了测试小姐姐的时间~~
事情的起因是这样的,我们有一个接口是对外修改状态用的,例如状态有1,10,20,30,40,50 等等,状态的流转在业务上来说只允许操作一次,不然会导致一些重复的事件触发。
所以为了防止并发修改导致的系统问题,我们在修改数据库的时候,做了一个 CAS 判断
1 | update tbl set status = ? where status = ? and order_id = ? |
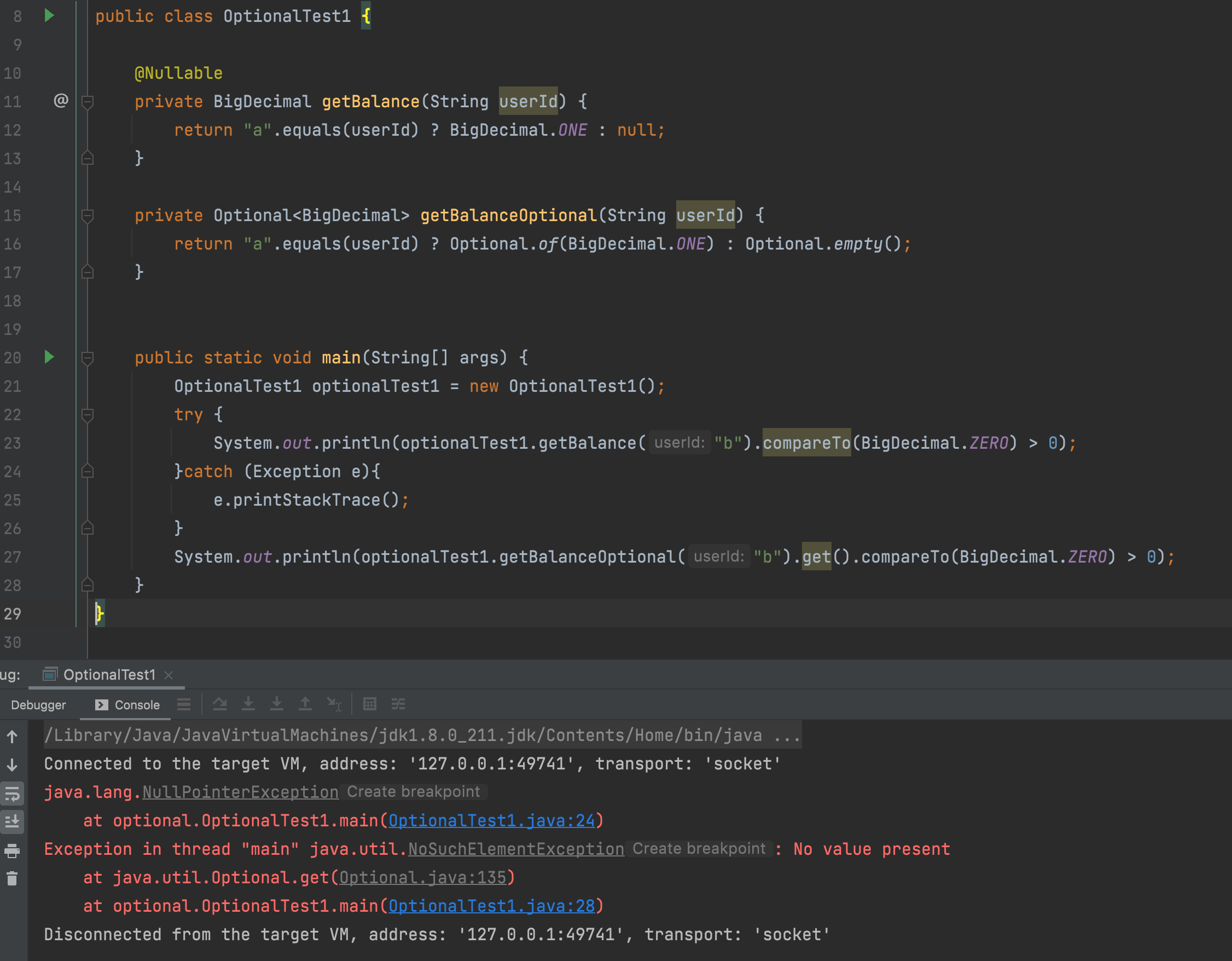
目前的项目中,JDK 版本已经全部是 1.8 以上了,项目函数式编程的代码多了起来,但是由于每个人的语言风格不同,如果滥用 JDK8 的各种函数式 API,会造成一定的坏味道
网上最多的说法是为了避免 NPE(NullPointException),但是我个人觉得这和说法不太成立,例如下面的一个方法:
如果没有明确的说明,本文的存储引擎均是 InnoDB,版本:8.0
假设一个表如下:
1 | CREATE TABLE `dy_video_list` ( |
目前数据有 2700 +