JDK1.7中的ConcurrentHashMap实现细节(二)
简介
在JDK1.7向JDK1.8升级的过程中,ConcurrentHashMap由原来的可重入锁和CAS锁直接被替换为synchronized关键字了,虽然说在功能上都是完全一致的,但是在这里一直都有一个疑惑,既然在1.7的使用过程中没什么问题,那到底是出于什么原因要将其替换呢。
JDK1.7中的ConcurrentHashMap
在JDK1.7中,其结构是由一个可重入锁Segment数组和每一个节点下的HashEntry数组来实现的。结构图如下: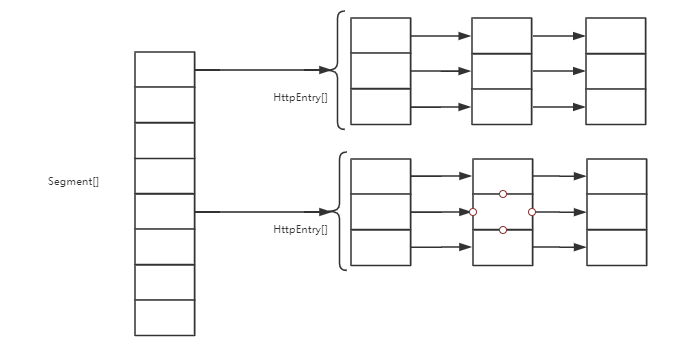
由于 segment 是一个锁,所以如果在并发的过程中,多个线程尝试向一个 segment 中的 HashEntry 进行插入的时候,只能有一个线程会获取到锁,其他的线程会被阻塞直至锁被释放,所以这个容器是一个并发安全的。
查看 put 方法的调用链的时候,可以发现最终都是调用的是Segment的put方法。
segment 类在 ConCurrentHashMap 中的变量是以一个数组的形式所存在的,由于segment继承了 ReentrantLock ,所以是它也是一个可重入锁,因此在JDK1.7里面,是通过 segment的 重入锁机制来实现并发的写入。同时也可以发现如果调用的是ConcurrentHashMap的无参构造函数的话,那么初始化Segment数组大小就是16,当然这个数组大小其实是可以被调整的,但是无论怎样进行调整,最终 segment 数组的大小永远都是2的n次方。
Segment
在ConcurrentHashMap里面,一个segment就是一个HashEntry的数组,而一个HashEntry就是一个bucket。
但是需要注意的是,ConcurrentHashMap 默认的 segment 数组的大小是16,也就是说最多只可能有16个线程同时进行处理
当调用 put 方法的时候,会通过一个可重入锁的 CAS 操作来尝试获取该 segment 锁,如果获取到了则直接新建一个 Node 节点,如果还未获取到则直接调用scanAndLockForPut方法
1 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
scanAndLockForPut方法的作用
在这个方法里面,会在 while 循环里面尝试 64 次,而且可以看到在这个循环语句里面有一些细节的操作。具体如下:
- 判断当前头节点 first 是否为 null,是的话则初始化 node
- 如果 first 不是 null,判断当前的 key 是否和 first 相等
- 如果 first 即不为null,并且当前的 key 又不和入参的key相同,则直接寻找其 next 节点,直至 next 为null,然后进行第一步
其实上面的一些步骤仅仅是该方法循环的第一步要做的,当上述三个步骤都进行完毕之后,首先会判断循环的次数是否已经大于 MAX_SCAN_RETRIES 如果是的话,则直接调用 lock 方法,如果不是的话则调用第三个判断。
第三个判断中会判断当前循环次数是不是偶数,如果是的话则会判断当前的头节点还是不是之前的first,如果不是的话则需要重新将新的头节点赋值给 first 然后将循环次数改成1,再次重试。
其实这个方法如果仔细看看,你会发现貌似没啥作用,因为返回的是 node,但是 node 一旦第一次被赋值之后,以后便不会做任何的更改,所以正如该方法的注释所说的一样,这个方法仅仅是为 JVM 做一个预热而已。
继续获取锁
如果在 64 次以内还是未获取到该锁,则会调用lock方法,由于 ConcurrentHashMap 在初始化 segment 的时候,并未显式调用ReentrantLock的构造方法,而 ReentrantLock 又是默认初始化非公平锁,所以此时在 scanAndLockForPut 里面的 lock 其实调用的是 NonfairSync 里面的 lock 方法,即再次以非公平锁的方式来尝试获取锁
1 | final void lock() { |
当最后一次如果 CAS 操作还未获取到锁的时候,segment 就会调用acquire(1)
1 | public final void acquire(int arg) { |
在这里可以看到的是 if 判断里面还是会再次尝试获取锁,当还未获取到锁的时候,就将该 Node 放入到 FIFO 队列的末尾,然后等待着被唤醒执行
从上面的一个流程不难看出,在 segment 首先会以可重入锁的方式来尝试性的获取锁,当没取到的时候会while循环64次做一个预热,如果在循环的过程中还是未获取到锁,则会进行两次CAS操作(分别在两个不同的方法里面),如果最终还是无法获取到锁的话,那么此时就会将自己放入到 AQS 中的 FIFO 队列。
回过头来再看 segment 里面的第一行代码:
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
那么可以看到的是,在JDK1.7里面,put方法如果在大量并发的情况下,如果要获取一个锁会进行非常多的操作,而且它默认的 segment 数组大小还是 16 ,也就是说map的所有键值,出现碰撞的概率不是 1/map.size(),而永远是 1/16。
JDK1.7中的ConcurrentHashMap实现细节(二)
https://somersames.github.io/2019/09/15/JDK1-7中的ConcurrentHashMap实现细节/