mysql中count(*)和count(1)的区别
在进行旧的项目 review 的时候,我发现绝大多数的统计SQL都是基于 count(1) 来进行的,只有一少部分是基于 count(*),那么这两种写法到底有什么区别。
mysql中,常用的存储引擎有myisam和innodb,但是由于myisam只支持表级别锁,而且还不支持事物,所以在mysql的5.5版本之后就将默认的存储引擎调整为innodb。
以下实验基于 Mysql8.0.1 来进行
首先这里准备了一个表.

在此之前先通过 show table status 查看表中的数据,如下:
1 | mysql> select count(*) from t_book; |
可以看到此时查询出来的ROWS是53935,那么再查看下通过索引查询出来的数据行数有多少呢? 可以看到show index from t_book 查询出来的数据如下:
其中有大概 238 条数据的统计差异,这其实是因为Mysql的show table status查询出来的只是一个估计值。
查看系统的show table status
在mysql的系统库中可以看到 t_book 表的相关信息,可以使用如下方式:
其中的n_rows就是之前查询出来的值,但是这一个值是一个粗略估计的值。
而 clustered_index_size 和 sum_of_other_index_sizes 则分别表示的是聚簇索引和其它的索引所占有的页的数量
回到之前的主题上来,那么下面就来看下
count(*)和count(1)的区别:
区别
首先打开 Mysql 的 warnings,便于分析日志:
1 | mysql> warnings; |
然后再分析下两个之前的差异:
count(*)

可以看到此时 count* 走的是一个二级索引,但是在 Note 里面可以看到最后 count(*) 还是被转换成了count(0)。
count(1)

而 count(1) 可以发现也是走的一个二级索引
索引的选择
在 Mysql 中,由于主键索引一般情况下是比二级索引大的,所以在Mysql中,如果有二级索引的话,那么Mysql一定会选择一个二级索引来作为 count 的字段。
但是当有多个二级索引的时候,Mysql又会如何选择索引呢?
首先以 book_page 为例:
1 | mysql> create index book_page on t_book(book_page); |
然后通过 count 函数查询如下:
由于 count(1) 执行结果与这个类似,就不放截图了
这个时候可以看到 book_page 的索引 key_len 是5,那么如果第二个 二级索引 的 key_len 比这个短的话,那么 Mysql 会该如何选择呢?
以 book_num 作为索引
1 | mysql> create index book_num on t_book(book_num); |
此时查看 count(*)和 count(1),可以发现 Mysql 选择的是 book_num 索引作为 count 的字段。
对比之前的索引的
key_len,你会发现Mysql在有多个二级索引的情况下,是会优先选择key_len较小的索引。

由于count(*)和 count(1)索引的选择是一样的,此时就不放 count(1) 截图
PS:为了验证索引的创建顺序对 Mysql count 的选择没有影响,因此在这之后,又测试了一遍,不过是先创建的
book_num,后创建的book_page,此时发现 Mysql 还是选择book_num作为索引。
相同的Key_len
如果此时两个二级索引的 key_len 相同,Mysql 又会怎样选择呢?
此时修改 book_num :
1 | mysql> ALTER TABLE t_book MODIFY book_num int(11) NULL; |
此时进行 explain:
再反复的测试之后,会发现 Mysql 在 相同的 key_len 下,会自动的选择最后一个创建的 最小 key_len 索引最为 count 索引。
索引的选择跟区分度有关系吗
将 book_page 的字段区分度弄的低一点。
1 | mysql> update t_book set book_page = 10 limit 10000; |
然后此时再查看 Mysql 是如何选择索引的。
此时还是选择的是 book_page 字段,如果再把 book_num 的区分度弄的更低呢?
1 | mysql> update t_book set book_num = 100 limit 30000; |
最后对比会发现,执行的还是 book_page 作为索引,那么这是为什么呢?
optimizer_trace 分析
首先打开optimizer_trace:
1 | mysql> SET optimizer_trace="enabled=on"; |
然后执行 count(1) 语句。最后查看结果如下:只截取关键信息: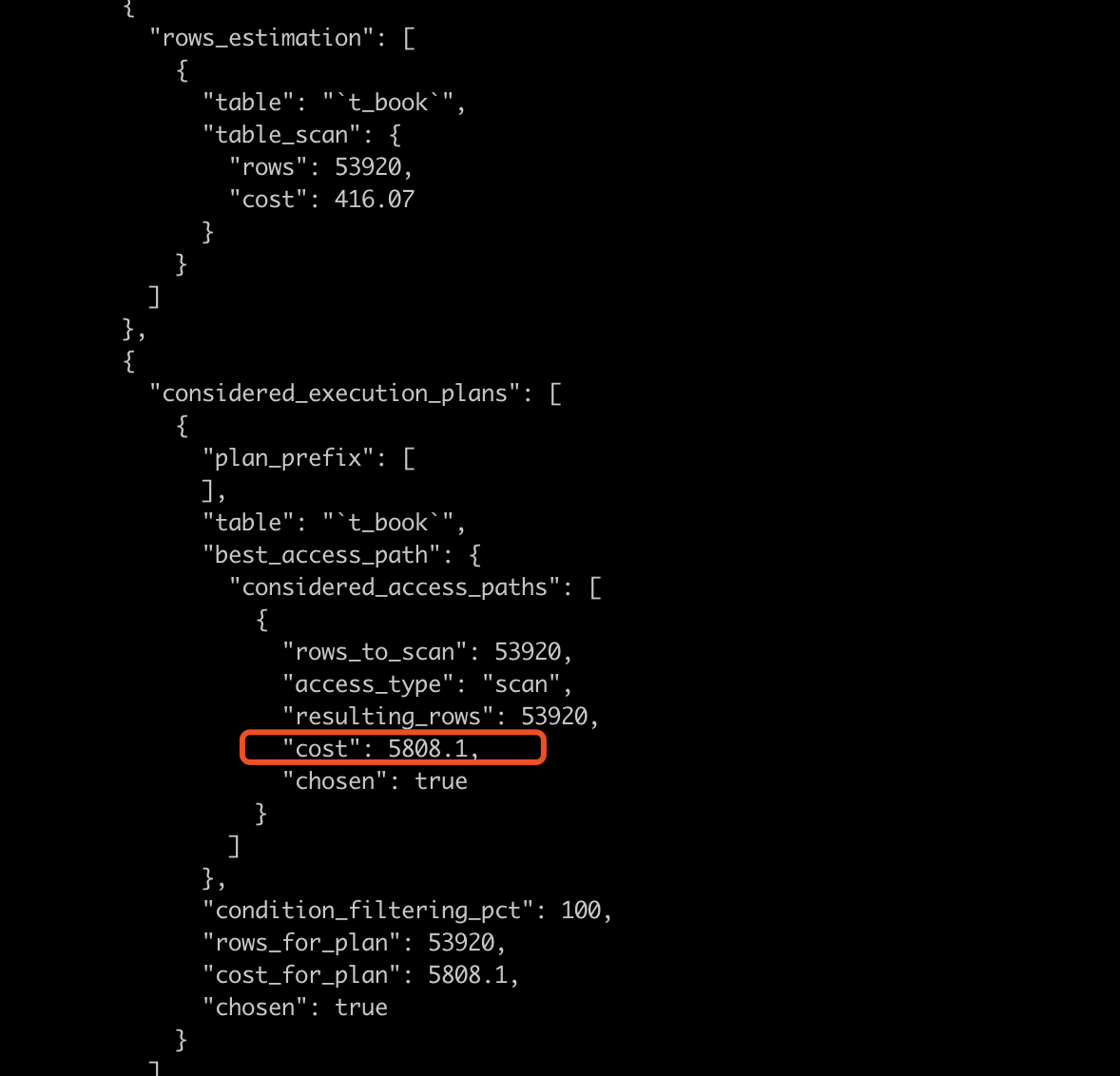
可以看到在使用 book_page 做索引的时候,Mysql认为其 cost 是 5808.1,那么对于 book_num 索引呢?
book_num
1 | mysql> select count(*) from t_book force index(book_num); |
执行完以后,查看 cost 如下: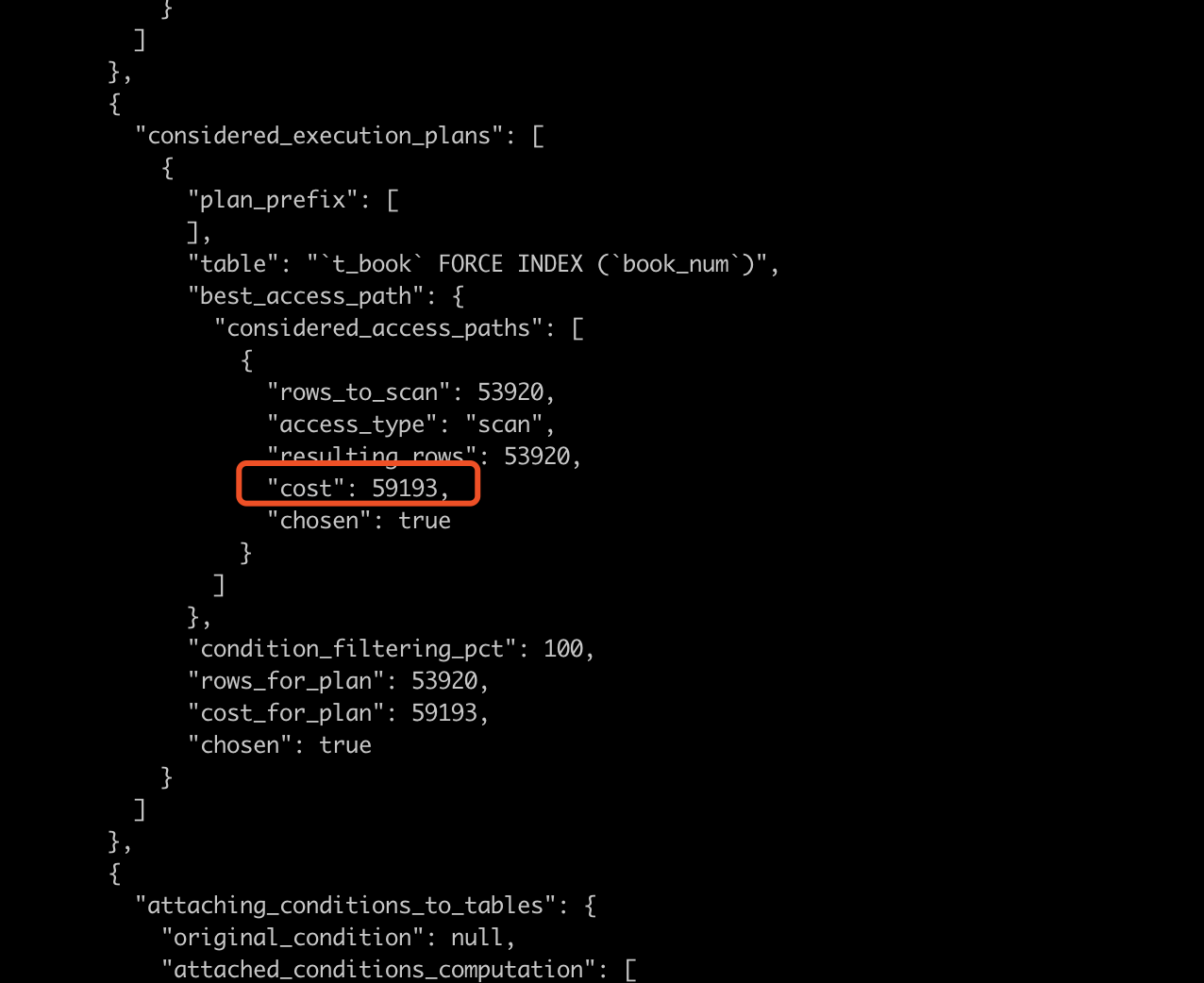
可以看到他的 cost 是 59193,所以 Mysql 认为 book_page 更加划算,那么是不是因为 book_num 的区分度太低,导致 cost 变大了呢?,此时调整 book_page 字段的值,如下:
1 | mysql> update t_book set book_page =1 limit 53000; |
然后会发现,Mysql 还是会选择 book_page 作为索引来进行 count,于是后来测试了下创建索引的顺序,发现当 key_len 相同的时候,Mysql是会选择首次创建的索引来进行 count,除非有更小的 key_len 出现。
总结
所以 Mysql 在选择 count 的时候,优先会选择 二级索引,当有多个 二级索引 的时候,会优先选择 key_len 小的,当有多个 key_len 相同的二级索引时,直接选择第一次创建该 key_len 的索引。
mysql中count(*)和count(1)的区别
https://somersames.github.io/2020/06/05/the-difference-between-count-and-count-1/