Redis中String的实现细节
String 是 Redis 中的基本数据结构之一,也是日常开发中使用最多的场景,例如秒杀扣库存,token缓存,详情缓存等,使用的频率还是比较高的,但是 Redis 中的 String 实现还是比较复杂的。
String 最底层的数据结构还是 char[],但是 Redis 在对数组进行封装的时候,做了一些细节上的优化
Redis 对象
在 Redis 中,每一个 Key 都可以称之为一个对象,Redis 包含了这个 Key 的类型,value 的内存地址,LRU 淘汰时间,引用计数等
1 | struct RedisObject { |
- type 表示这个对象的类型:String、list、set、zset、hash、stream、module
- encoding 表示该 Key 的 value 以什么类型存储,在 Redis 中有如下几个:
1
2
3
4
5
6
7
8
9
10
11 - lru 代表的是该 Key 被最后一次访问的时间
- refcount 表示的被引用的次数,当refcount 为 0 的时候,对象就会被回收
- *prt 代表的是内存指针,指向真正存储该 value 的内存区域
SDS
SDS 是 Redis 中字符串的具体实现,其结构如下:
1 | struct SDS { |
- len 表示的当前所使用的长度
- alloc 表示的是分配的内存大小(去除了 sdshrd 以及末尾的结束字符)
- flags 则是一个 8bits 的变量,前三位表示类型,后 5 位暂时还没使用
- buf 是字符串具体存放的地址
flags 的几种含义
Redis 中的 String 有几种 sdshdr,分别是:
1 |
在这里面,SDS_TYPE_5 基本不会使用,因为只能存放 32 个字符串,有一种特情况是,如果设置的字符串长度为0,会直接使用 SDS_TYPE_8,而不是 SDS_TYPE_5
字符串的存储方式
假设现在分别有两个字符串需要存储,分别是 a 和 aaa…aaa(100)个,常见的做法是直接为这两个字符和都开辟一块内存。
但是 Redis 使用的是内存进行存储的,可以存储多少数据完全取决于内存容量的大小,在内存不变的情况下,能存储多少数据取决的每一个 value 的大小,所以 Redis 的作者对 String 的存储进行了优化。
前面提到过 Redis 的对象有一共有五个字段,其分别如下
在 64位操作系统的机器上,Redis 对象的大小是 64 bits,那么剩下的 48bits 是否就可以利用起来存储 String 呢?
于是 embstr 这种存储方式就出现了
embstr
上面提到 Redis对象剩下的可存储容量是 48bits,那么可以真正用来存储字符串的有多少呢?
阈值计算
首先 RedisObject 自己就需要占用 16 个字节,所以剩下可以给 SDS 用的也就是 64 - 16 = 48 字节
前面提到了 SDS 的结构,首先 sdshdr 就需要占用 3 个字节,而且 sds 字符串结尾需要以 NULL 结尾,所以由占用了一个字节,那么最终的阈值就是 44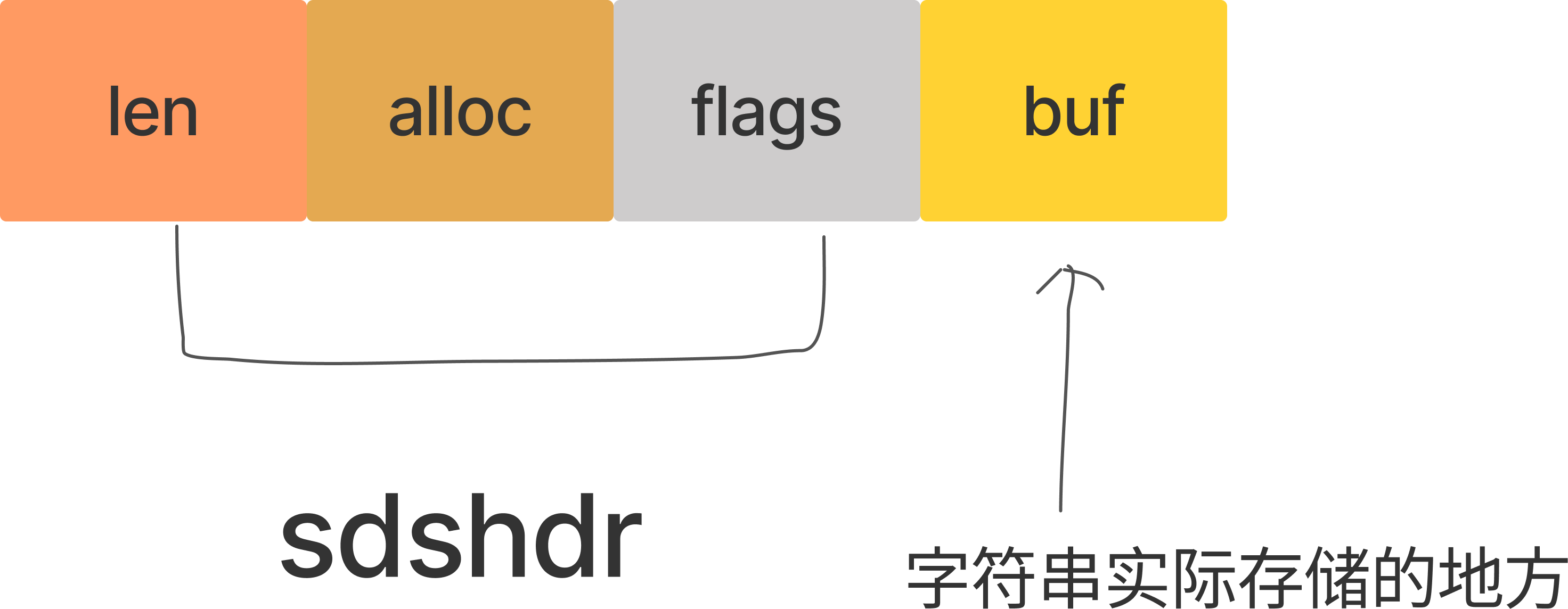
也就是当设置的字符串长度小于等于 44 的时候,Redis 将会直接将 SDS 拼接到 ptr 之后,避免新开辟一块内存区域
Redis 测试
在这里设置了一个Key a,它的长度刚好是 44,于是对 a 进行debug
1 | 127.0.0.1:6379> set a '12345678901234567890123456789012345678901234' |
可以看到 a 的编码方式刚好是 emdstr,那么再增加一个字符呢?
1 | 127.0.0.1:6379> set b '123456789012345678901234567890123456789012345' |
可以看到 b 的编码方式已经变成 RAW 了。
RAW 编码
当字符串长度大于 44 以后,就会将编码方式改为 RAW,Redis 会新开辟一块内存区域来存储 SDS,并且将 ptr 指针指向该内存区域
1 | robj *createObject(int type, void *ptr) { |
在使用 Redis 的时候,常用的还有 incr 和 incrBy,那么 Redis 又会以怎样的方式存储呢?
int
当通过 set 命令设置的 value 可以被转换为 long 类型的时候,Redis 就会尝试将其作为 int 的方式进行存储,int 方式存储本质上也是将其和 ReidsObject 放在一起
1 | 127.0.0.1:6379> set a 123 |
Redis 是如何进行判断的?
在 src/object.c 文件中,tryObjectEncoding 方法详细的做了详细的判断,在这里有一个小细节就是 Redis 采用了一个对象池来复用 1 到 10000 之间的数字,复用的条件限制如下:
- Redis 没有设置最大内存限制
- Redis 的设置了淘汰算法,但是淘汰算法不是 LRU 或者 LFU
1 | /* Try to encode a string object in order to save space */ |
Redis中String的实现细节