Redis中ziplist的实现二
添加 entry
ziplist 的添加过程大致如下:
如果是一个新建的 ziplist,其中新增元素的时候,直接将 prevlen 设置为 0 即可
如果是在中间位置新增,那么首先需要获取前一个 entry 的长度,因为后面的元素已经计算过了,因此直接拿来用即可
如果是在尾部进行新增元素,那么需要计算其前一个元素的长度,因为 zlend 不会保存前一个最后一个尾节点的长度,因此需要在新增的时候计算
连锁更新
由于 ziplist 的设计,当前一个元素长度小于 254 的时候, prevlen 会以一个字节进行存储,但是当前一个元素大于 254 的时候,那么 prevlen 就会变成 5 个字节
1 |
|
其中前一个字节固定为 FE,后面四个字节存储的是前一个 entry 的长度,这个也很好理解,
为什么是 254
因为 ziplist 也需要像其他的双向链表一样,需要有一个 head 和 tail 来表示头尾,head 节点因为前面没有 entry,所以 prevlen 是 0,而尾节点 redis 作者就将其设置为 255,当遍历的时候,如果遇到 prevlen 的值是 255 的就表示该节点是一个尾节点。
所以在 redis 的源码中也经常看到 ptr[0] == 255 这种判断来判断是否是尾节点
连锁更新触发的场景
因为 redis 的 prevlen 存在两种存储方式,如果前一个节点的长度发生变化,那么不可避免的需要更新后续的 entry
例如原有的 ziplist 的 entry 如下: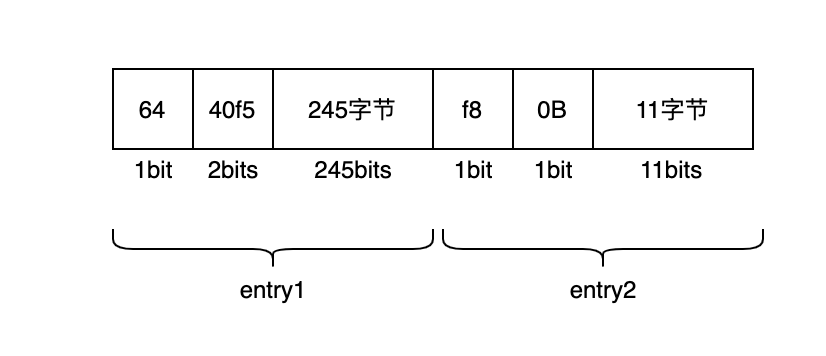
现在需要在 entry1 和 entry2 之间新增一个 entry,如果新增的 entry 长度大于 254,那么 entry2 的 prevlen 势必会需要扩容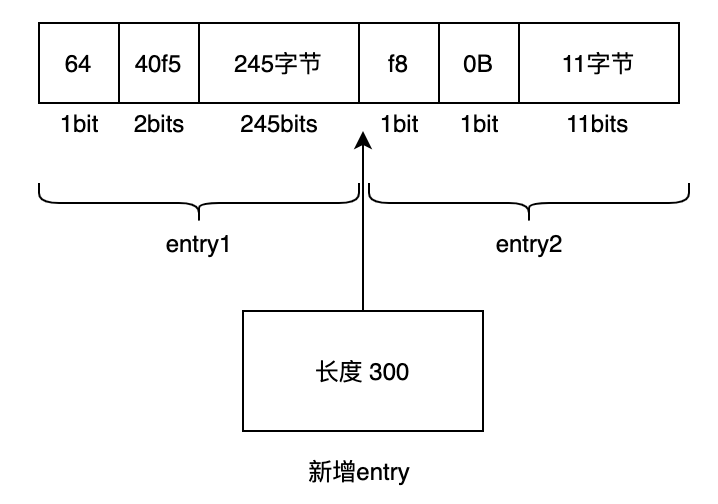
此时由于新增的 entry 长度已经大于 254,所以 entry2 的 prevlen 需要由 1个字节扩展到 5个字节,而且还会进行递归进行下去,一直到后一个节点的 prevlen 不需要更新为止
使用场景
在 redis 中,list、zset、hash 在数据量小的时候都会使用 ziplist 作为其存储数据的结构,而且三种结构都支持自定义的配置:
1 | /* Zip structure config, see redis.conf for more information */ |
其中 list 的配置少了一个 _value,是因为 list 这种数据后续无论怎样存储都会是一个双向链表,不用考虑每一次 value 的大小,但是最后如果元素 > list_max_ziplist_size,则会变成 quicklist
Redis中ziplist的实现二