CyclicBarrier详解
在上一篇的文章中有提到过 CountDownLatch ,其实 CyclicBarrier 也有异曲同工之妙,不过 CyclicBarrier 是等到所有的线程都到达一个点以后,然后再一起执行
有点像小时候一起去春游,必须等到所有的同学都到了学校,才能一起去坐车,不然就会一直等待。
构造函数
CyclicBarrier 的构造函数有两个,分别如下:
1 | public CyclicBarrier(int parties) { |
1 | public CyclicBarrier(int parties, Runnable barrierAction) { |
其中的 int 表示当多少个线程到达指定的位置时,然后一起执行,而 Runnable 的含义暂且在这里不说明,文章后面会进行说明
如果要实现线程的同时执行,那么肯定是要进行线程间通信,如果忘记了不要紧,这里我给大家补一下。
Java 中的线程通信
常见的通信机制,有如下几种:
- 锁
- 等待/通知机制
- 信号量
- 管道
- join方法
回到 CyclicBarrier,如果由你来设计的话,会选择哪一种呢?
所有的线程在到达一个点以后,都可以执行,是不是马上就会想到 Object 里面的 notifyAll() 呢?
新建一个共享对象,然后每一个线程在调用 await 方法的时候,就会自动加入这个对象的等待池,最后一个到达的看下是不是成 0,是的话就通知所有的线程起来干活。
如果你这样想就错了,Object 里面的 notifyAll 是需要配合 synchronized 一起使用的,所以如果你用的是 Object 方法里面的 wait,那么就需要在外面使用 synchronized 了,那么问题就来了,大叔为啥不用呢?
还是回到这个类的场景,我们的目标是最后一个线程在调用 await 方法到 0 以后,所有的线程就会被唤醒,这个类出现是在 JDK1.5,那个时候 synchronized 还是重量级所,是在 JDK 后续迭代的时候引入了「锁升级」这个概念,从而性能才有了提升。
所以猜测 Doug Lea 大叔就放弃了 synchronized,反而采用的是 Lock/Condition 这一套来实现的
原理
await
CyclicBarrier 里面的主要逻辑就在于 await 方法
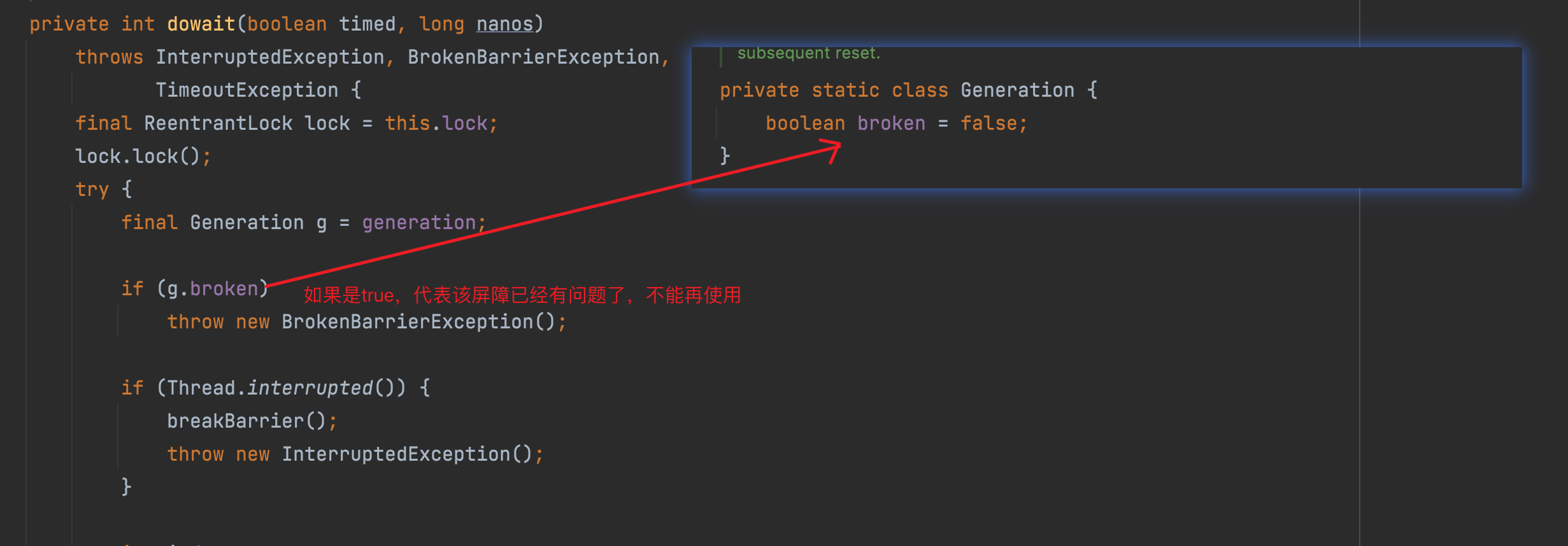
当调用 CyclicBarrier 的 await 方法以后,首先会加一个重入锁,然后会判断当前的「屏障」是否被终止了。
被终止的原因有很多,例如线程被中断,最后执行 Runnable 失败等等。
继续往下走,当 count 减少至 0 的时候,表示该条件队列上的所有线程都可以执行
等于0
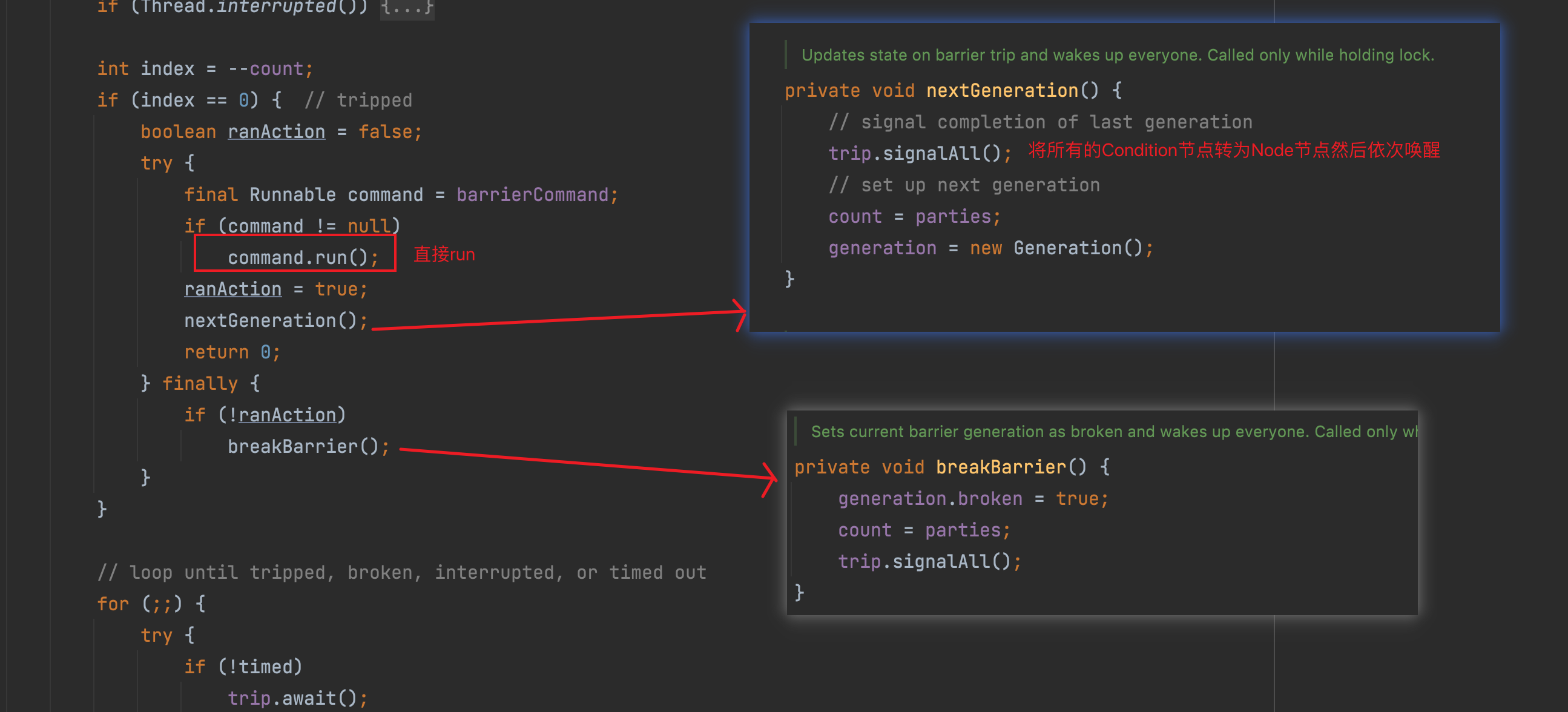
在这里有一个判断,还记得之前提到的第二个构造函数的第二个参数吗,就是这个 barrierCommand,当通过第二个构造函数传入进来一个 Runnable 方法以后,在 count 减少至 0 时(表示所有的线程已经到了指定位置),就会执行这个 Runnable,但是这里并不是起一个新的线程,而是直接在当前线程 run。
PS:顺带提一句如果父线程需要感应到子线程的话也有方法,不过这个更加简单粗暴了
在执行完 command 以后,就会直接调用 nextGeneration方法了,此时就会唤醒所有的 Condition 节点,然后重新初始化一个新的 Generation,而 Generation 的构造函数默认 broken 是 false,所以就相当于重置了 CyclicBarrier。
nextGeneration 有两个变量,分别是 parties、count,其中 parties 是从构造函数带过来的,count 则代表当前的剩余未到达指定地点的线程,每一次 count 为 0 以后,在重新初始化的时候,count 就会被重新赋值,继续往下走。
如果 Runnable 执行出错了,那么就会进入 finally,因为 ranAction 是 false,所以调用 breakBarrier 设置当前 CyclicBarrier 不可用,同时唤醒所有的 Condition 节点,因为 finally 里面已经设置了 broken 为 true,所以这里就会判处一个异常,不过条件队列中的其他线程都会被执行,只有最后一个线程会因为异常导致不会执行后面的代码
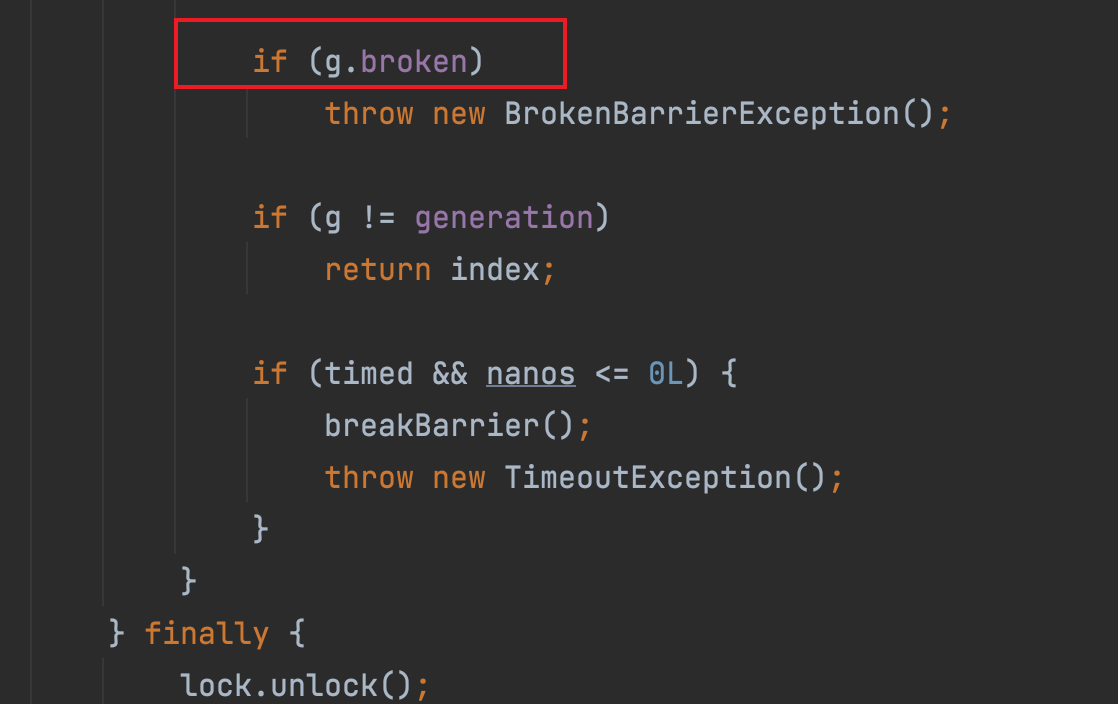
不为0
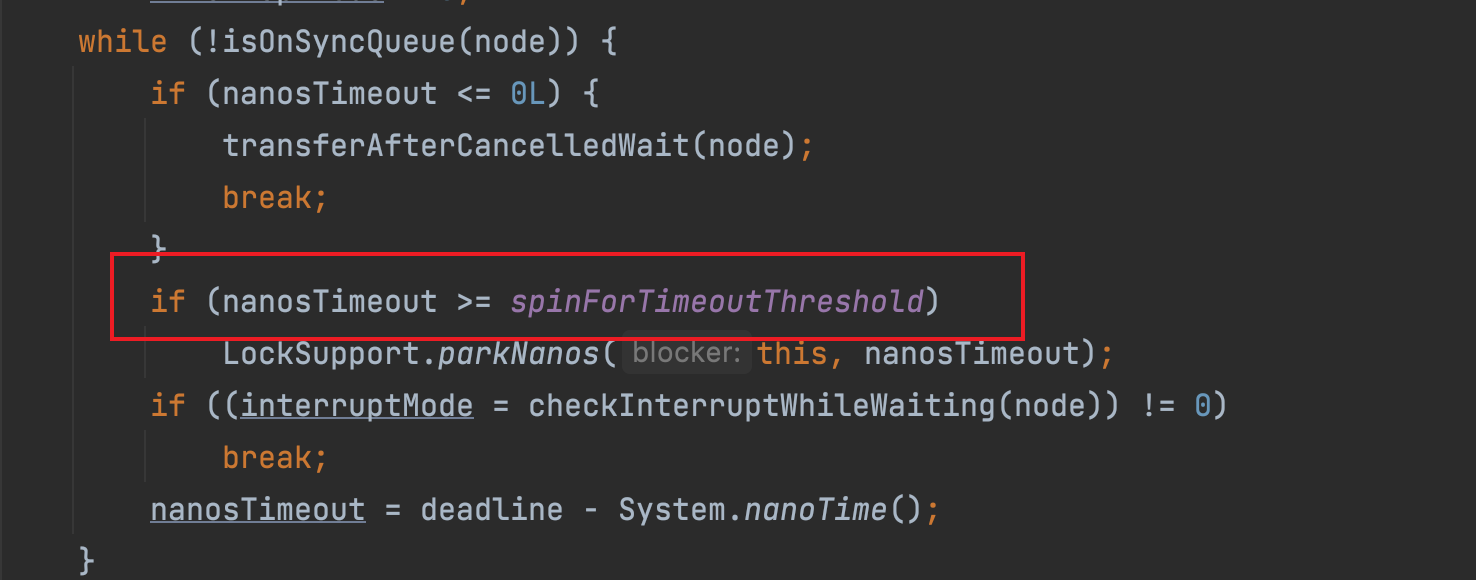
当线程执行到这里不为 0 的时候,首先会判断是否设置了超时时间,最终会调用 trip 的 await 两个方法,只不过 awaitNanos(long nanosTimeout) 在等待 nanosTimeout 以后会自动的返回,而 await 则会一直等下去
其中 awaitNanos(long nanosTimeout) 本质上是使用 LockSupport.parkNanos(this, nanosTimeout) 来实现,只不过 Condition 在判断如果 nanoTimeout 时间小于 1ms 的时候,就会直接进行自旋。
条件队列Condition
要理解条件队列,首先就需要理解 AQS 里面的队列,在 AQS 里面有两个队列,一个是基于 prev、next,而另一个就是基于 nextWaiter
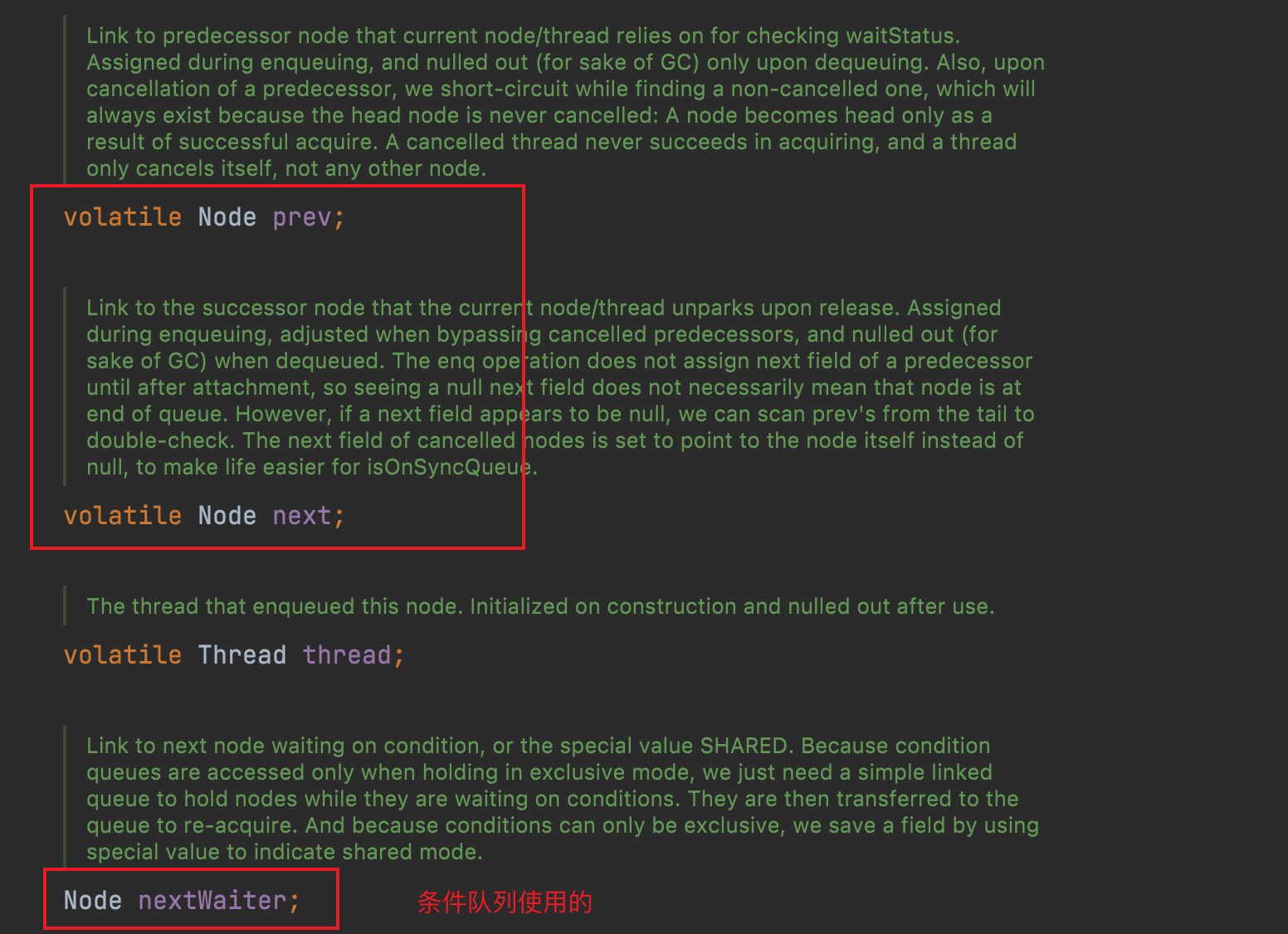
其中,如果 CyclicBarrier 中的 count 如果不为 0 ,那么一直是通过 nextWaiter 进行连接,而一旦 count 变成 0,那么所有的 条件节点就会立刻变成另一个 Node 双向队列,然后挨个被唤醒

关于 Condition 为什么需要转换成 node 双向队列的思考
首先如果在 Condition 中在实现一套 AQS 逻辑的话就会和现有功能冲突了,既然 AQS 已经有现有的功能,那就直接复用 AQS 的功能即可,不用再重复造轮子了
其实 Condition 的节点也是一个 Node,那么既然都是 Node,为什么 Condition 会单独的自己称之为一个链表呢?
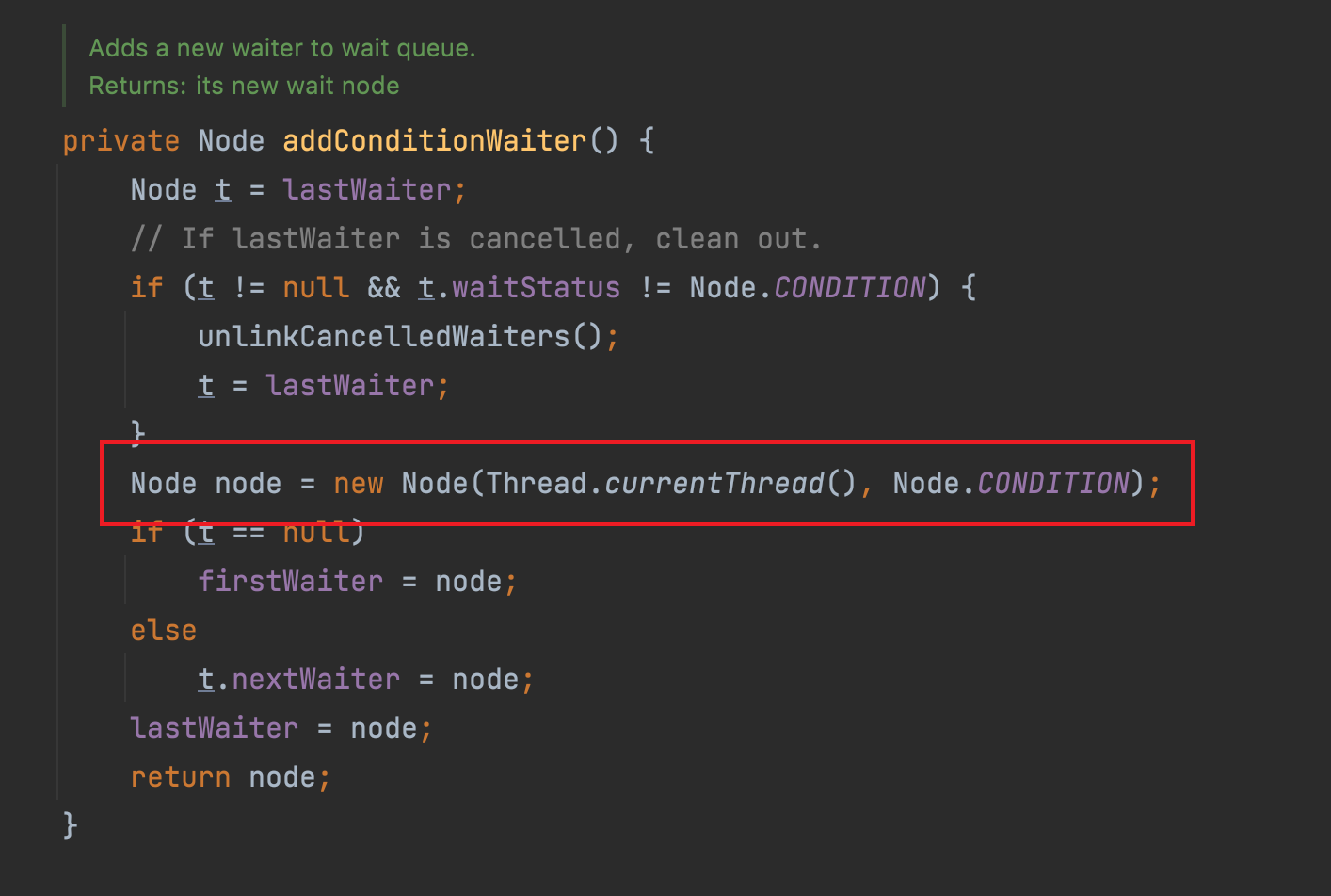
因为 Condition 和 ReentrantLock 是一起配套使用的,那么大家想过一个问题没有,ReentrantLock 的入队是通过 next 和 prev 来指向头尾指针的,如果 Condition 的 Node 也是用 next 和 prev 的话,会极大的增加 AQS 的每个方法的复杂度。
例如:
现在有十个线程在争抢资源,线程一抢到了资源,那么其他线程自然就会进入 AQS 的队列里面去,而此时线程一又向 AQS 队列里面塞了几个 Condition 节点,而恰巧就在其余九个 Node 之间塞了几个?是不是想骂人了。
唤醒的时候恰好遇到一个 Condition 节点,head 指针指向谁呢?后移的话,那万一条件队列全部满足了,需要执行,是不是又得从前向后挨个再次遍历。
所以这个猜测 Doug Lea 老爷子受不了这个混乱逻辑了,干脆就在 Condition 中用 firstWaiter 和 lastWaiter来表示头尾指针,然后在 AQS 中用 nextWaiter来表示一个单链表,然后条件队列自己玩去~~等需要唤醒的时候,直接转换成 AQS 的队列,复用现有逻辑就成
CyclicBarrier详解