记一次parallelStream错误使用导致的NullPointerException
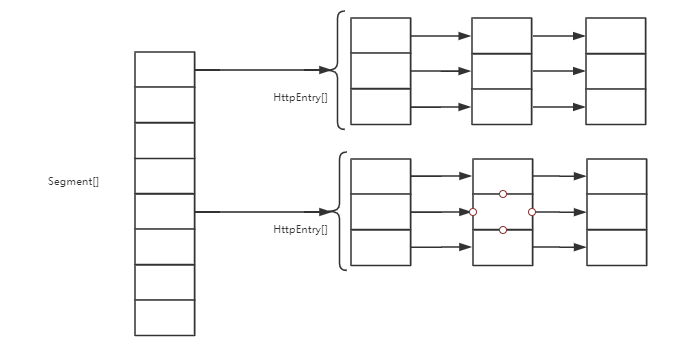
parallelStream
在 Java8 中,新增了一个很有用的功能就是 流,这个功能可以使我们可以快速的写出优雅的代码,其中 stream 是一个串行流(说法可能有误…就是不会采取多线程来进行处理)。还有一种就是 parallelStream 采用 ForkJoinPool 来实现并发,加快执行效率。
所以在使用 parallelStream 的时候一定要注意线程安全的问题,首先看一段代码: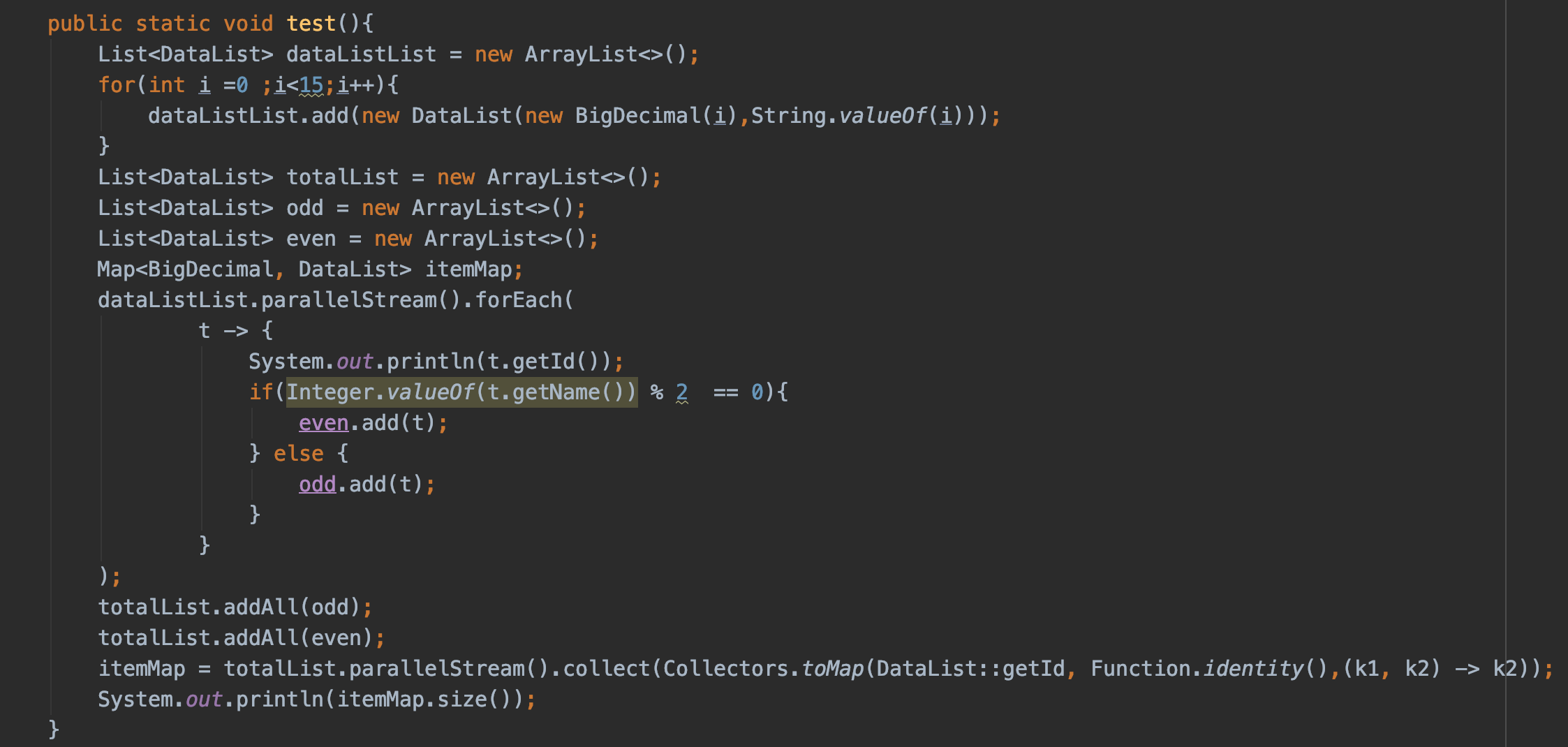
在这段代码中,是首先判断 dataListList 里面对象的 name 属性是否是偶数,是的话则添加至偶数List,反之则添加至奇数List。
然后开始测试这段代码: