JDK1.7和1.8中的HashMap区别
Jdk1.7和1.8中,HashMap的一些关键点几乎重写了。
主要变更点:
1. hash扰动算法
在jdk1.7的时候,HahMap的hash扰动算法如下:
1 | static int hash(int h) { |
而在jdk1.8的时候,其hash算法已经修改为如下了:
1 | static final int hash(Object key) { |
HashMap在放入一个元素的时候,首先会获取其HashCode,然后将 key 的 HashCode 进行扰动,避免同一个碰撞概率太大。
如下例子。
假设一个key a 的 hashCode 为 1010 1010 1110 1101 1110 1111 1000 0110,如果不进行扰动,那么直接与table的长度 -1 进行与运,若table的长度是16,则计算的过程如下:
1 | 1010 1010 1110 1101 1110 1111 1000 0110 |
计算结果得出: a 的数组下标就是 6
但是这样就会出现一个问题,即每一次比较的都是最低位,如果某一个 key 和a的高位不同,低位却相同。每一次都是取最低位的几个数值进行运算,那么就会产生很严重的hash碰撞,所以就需要进行hash扰动以减少hash碰撞的概率。
以 jdk1.8 的扰动算法为例
1 | 1010 1010 1110 1101 1110 1111 1000 0110 |
为什么进行扰动后,碰撞的概率会降低。具体的原因可以阅读这边文章
An introduction to optimising a hashing strategy
2. HashMap的数据结构出现了变化
在 jdk1.7的时候,HashMap是由一个数组和一个链表构成的。
插入规则如下:
- 计算新插入的 key 的 hashCode,然后通过 hashCode 计算索引,找出该key在
Entry中的位置,然后判断该下标是否有元素,如果没有则直接进行插入。
- 如果有的话就按照如下规则找出是否有相同的 key:
hash相同且key相同
hash相同且equals方法返回相同
若相同,则直接将当前的 value 替换原来的 value。
- 如果最后还是未发现相同的 key ,则新建一个
Entry,并将头节点设置为该Entry。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //找出原来table中的元素
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
//注意,此时将该节点是作为现在的table的头节点,原来的e则是新节点的next
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
以下是在 jdk1.7 的时候第三种方式插入的极简版: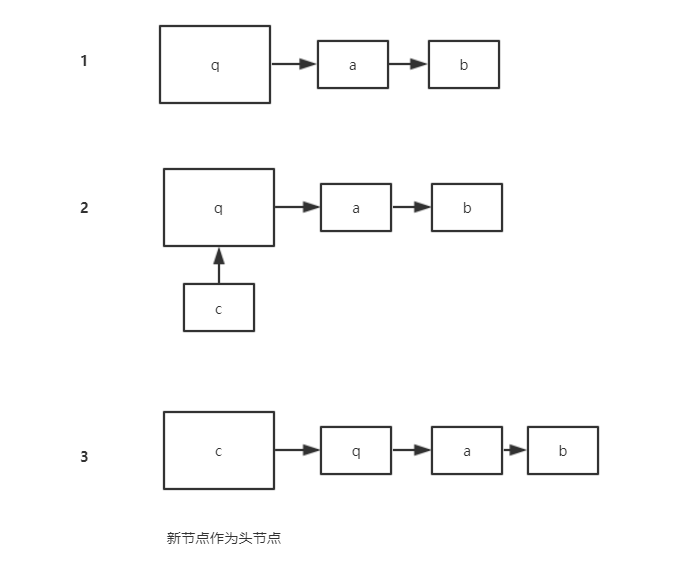
而在 jdk1.8 的时候,则是由一个数组加一个链表、红黑树组成
之所以这样改进,是因为在极端情况下,如果所有的元素都 hash 到了一个下标,那么这样的话,HashMap在查找元素的时候就会退化到一个链表,其时间复杂度是O(n)。
为了应对这种情况,HashMap在1.8的时候会判断链表上的元素,如果超过了 8 个,就会将链表转化为红黑树。同时在 1.8 的时候,HashMap将链表的插入方式修改为尾插入。
提示:修改为尾插入是为了避免在并发的情况下出现链表成环(在jdk1.7之前会出现、同时HashMap并不适用并发场景下)
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
上述的变动最大点在于这两行代码:
1 | p.next = newNode(hash, key, value, null); |
第一行是进行尾插入(1.7是头插入)
第二行是大于8会进行链表到红黑树的转化
jdk1.7采用头节点插入导致的链表成环
虽然HashMap是一个非线程安全的,但是如果在 jdk1.7 版本中将HashMap用于并发环境下会出现什么情况呢?
1 |
|
第一步
此时假设线程二已经将hashMap扩容完毕,但是线程一还在被挂起。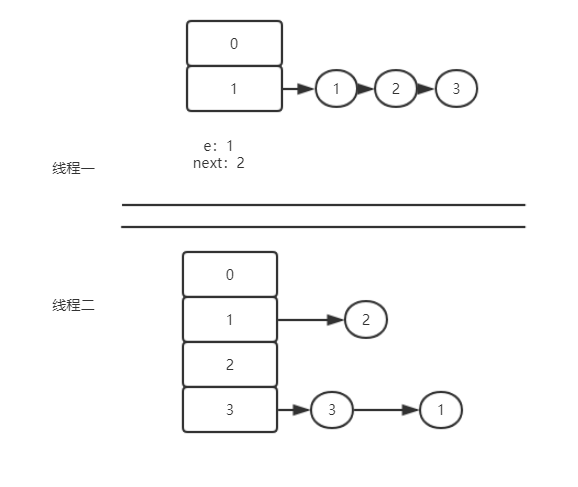
线程一执行,此时 e是为1,next却是2。
![]()
线程一第一次循环执行完毕,此时的e是2,然后`e.next是3。
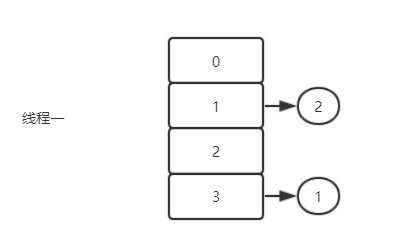
线程一第二次循环执行完毕,此时的e是3,然后e.next是1,注意此时线程二中,已经将 3 的next指向了 1 ,所以此时e是3,然后 next 是1。
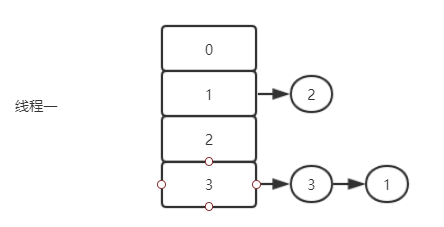
此时第三次循环完毕,由于e还不为空,于是进行第四次循环(主要原因是线程二已经将3的next指向为1)。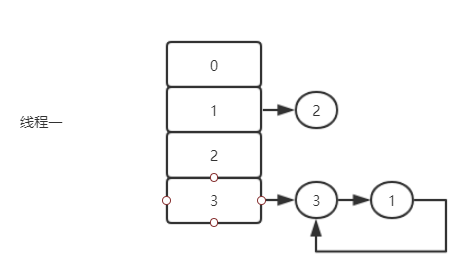
由于1的 next 是 null,所以循环结束。
jdk1.8的尾节点插入
由上面的分析可以不难发现,造成链表成环的主要原因为:多线程下,头节点插入导致原来的链表的尾节点有了next,所以最后会多循环一遍,从而成环。
而在jdk1.8采用的为节点插入在多线程下,顶多是另一个线程把前面一个线程 resize 的过程再重复一遍,却不会再出现链表成环。
多线程下通用的bug
虽然 jdk1.8 修复了链表成环这一个问题,但是多线程的情况下导致的数据丢失问题确实一直存在的。
所以不要尝试在多线程的情况下使用HashMap,如果需要用到Map结构的话,可以用CurrentHashMap或者HashTable
JDK1.7和1.8中的HashMap区别
https://somersames.github.io/2019/04/08/JDK1-7和1-8中的HashMap区别/